Gist, Blur, and Attention
Analyzing Temporally Averaged Visual Representations for Alignment with Human Engagement Signals

Abstract
Standard Vision-Language Models (VLMs) excel at semantic extraction from raw video frames, but it remains unclear if these machine-centric representations align with human temporal integration and memory processes relevant to phenomena like viewer engagement or memory salience. This paper investigates this alignment by contrasting standard VLM analysis (Llava-OneVision on raw clips) with a human-inspired alternative: the Average Image Pathway. This pathway generates representations by sampling W frames uniformly across the full 10-second clip duration and averaging them, explicitly modeling temporal integration to emphasize spatio-temporal stability akin to scene gist. We extract ResNet-50 features from these temporally averaged images. Our central hypothesis was that features from optimally averaged images would better align with human engagement signals (YouTube replay data) compared to direct VLM analysis. We conducted an ablation study varying W (the number of uniformly sampled and averaged frames) and performed a core comparison using a dataset of 61 city walk videos (50,380 clips) with regression models evaluated via cross-validation.
Our findings indicate that comprehensive temporal integration via fully averaged images (W=Full) yields ResNet-50 features that significantly outperform direct VLM embeddings in aligning with viewer replay signals, achieving a 36.4% improvement in R² (R² of 0.106 for W=Full vs. 0.0777 for VLM). This suggests that representations emphasizing stable scene content, a product of temporal integration, are more indicative of human engagement than VLM-derived semantics from raw frames. This work (1) introduces temporal averaging as an analytical probe for human-aligned representations, (2) demonstrates the superior alignment of features from comprehensively averaged images over direct VLM processing through controlled experiments, and (3) underscores the value of incorporating human-inspired temporal integration for developing video understanding models more attuned to human perception. We acknowledge limitations, including the proxy nature of replay signals, and propose human validation for future work.
1. Introduction
1.1. Motivation: Aligning Machine Perception with Human Temporal Processing
Humans perceive dynamic scenes by continuously integrating visual information over time, forming stable representations that allow for understanding, recall, and judgments of interest [9, 11, 15]. Modern AI, particularly large Vision-Language Models (VLMs), achieves impressive feats in video analysis by processing dense sequences of frames [8]. However, standard VLM approaches typically focus on high-fidelity frame processing. A fundamental question in computer vision arises: do these machine-centric representations align with the integrative and abstractive processes underlying human visual memory and engagement? This potential misalignment becomes a critical factor in the analysis of signals reflecting human behavior, such as viewer replays in long videos (moments viewers collectively revisit), as it directly influences the validity of conclusions drawn about human engagement. Can we design and evaluate video representations that better reflect human-like temporal processing?

1.2. Problem Statement and Research Gap
YouTube replay heatmaps provide a large-scale signal reflecting collective viewer re-engagement, potentially linked to interest, memory salience, or confusion. While VLMs can extract rich semantics from raw video clips (a “machine understanding” baseline), there is a significant research gap in evaluating whether representations inspired by human temporal integration – emphasizing stable structures over transient details – show better alignment with such behavioral signals.
Prior work often focuses on maximizing predictive performance for general engagement metrics or employs complex dynamic models [7, 2], leaving unexplored the systematic comparison of simple, human-inspired averaging strategies against standard VLM processing using replay data as a quantitative benchmark for alignment with engagement phenomena. This gap is particularly relevant to computer vision, as it touches on the fundamental question of whether machine perception should mimic human-like temporal integration to better align with human behavioral signals.
1.3. Proposed Approach: The Average Image Pathway with Variable Integration Density
To investigate this alignment, we propose and evaluate the Average Image Pathway. This approach is inspired by cognitive concepts of temporal integration and gist perception. For each 10-second video clip, we generate an “average image” Iavg(W) by:
- Sampling W frames uniformly distributed across the clip’s entire 10-second duration from the original video clip file (using np.linspace to determine frame indices).
- Calculating the pixel-wise average of these W sampled frames.
This method explicitly models temporal integration, ensuring the resulting average image reflects contributions from the entire clip duration, while emphasizing stable scene elements and smoothing transient details. Crucially, we treat W (the number of frames sampled and averaged) as a parameter, allowing us to systematically study how different levels of temporal sampling density and integration affect the resulting representation. We then extract 2048-dimensional visual features from these averaged images using a pre-trained ResNet-50 CNN. This allows a controlled comparison where the core difference lies in the input representation: the VLM pathway extracts semantic embeddings from raw video frames, while the Average Image pathway uses standard CNN features from temporally averaged images created with varying sampling densities (W). The goal is to assess which representation better aligns with the replay signal.

1.4. Research Questions and Hypotheses
This study addresses two fundamental computer vision questions:
- (Ablation) How does the density of temporal integration, controlled by the number of uniformly sampled and averaged frames W, affect the alignment (measured via correlation with replay scores) of features derived from the Average Image Pathway? Is there an optimal W for maximizing this alignment?
- (Core Comparison) Do features derived from the optimally averaged images (ResNet-50 features from Iavg(W=optimal)) exhibit a stronger correlation with viewer replay scores compared to features derived from direct VLM analysis of the raw video clip (Sentence-BERT[10] embeddings of VLM-extracted keywords)?
Our central hypothesis is that an optimal level of temporal sampling and averaging (an optimal W) will yield ResNet-50 features from averaged images whose correlation with viewer replay scores better reflects principles of human temporal integration compared to semantic embeddings from direct VLM processing of the raw clip.
1.5. Novelty and Contributions
This project’s novelty lies in several aspects:
- Focus on Representational Alignment: It shifts the focus from pure prediction to evaluating how well different video representations (standard vs. human-inspired) align with a signal reflecting human engagement, using temporal averaging as an analytical probe.
- Systematic Parameter Analysis: It uses the number of averaged frames (W) as a controlled parameter to analyze the trade-off between temporal context integration density and representation quality, measured by alignment with the replay signal.
- Novel Comparison Framework: It establishes a rigorous framework for comparing direct VLM semantic analysis (keywords and embeddings from raw clips) against the Average Image pathway (which utilizes CNN features from temporally averaged images), using controlled experiments to assess alignment with human engagement signals.
- Computer Vision Insights: It provides insights into how temporal integration affects the information captured in visual representations, a key consideration for designing better video understanding models.
The main contributions are: (1) A technically sound evaluation framework comparing features from direct VLM analysis of raw clips against features from CNN analysis of temporally averaged images, using replay data as a benchmark for alignment with human engagement signals, (2) An empirical analysis of the impact of temporal averaging density (W) on this alignment, and (3) Initial insights into the potential benefits of incorporating human-inspired temporal integration principles into video representation design.
2. Related Work
Our research intersects with several key areas: video understanding with modern neural architectures, particularly Vision-Language Models (VLMs); cognitive science literature on human visual perception, temporal integration, and memory; and the prediction of viewer engagement signals.
2.1. Video Understanding with Vision-Language Models and Temporal Processing
Vision-Language Models (VLMs) such as Llava [8] and Video-LLaMA [13] have demonstrated remarkable capabilities in bridging visual and textual modalities. These models typically process video as sequences of frames, often employing sophisticated attention mechanisms like those in VideoViT[3] to generate textual descriptions, answer questions, or perform other complex video understanding tasks. For instance, Video-LLaMA explicitly integrates visual and audio encoders with a large language model to achieve nuanced video comprehension. While these models excel at extracting detailed semantic information from individual or sparsely sampled frames, their inherent temporal processing often focuses on capturing dynamic events or short-term action sequences rather than the long-term, temporally integrated “gist” that might be crucial for sustained engagement or overall scene memory.
The challenge of effective temporal modeling in videos is a long-standing one. Early approaches utilized 3D Convolutional Neural Networks (3D CNNs) [16] to learn spatio-temporal features directly. More recently, Transformer-based architectures like TimeSformer [2] and VideoMAE [12] have explored various forms of spatio-temporal attention and self-supervised pre-training strategies to learn robust video representations. These models often aim to capture complex motion patterns and temporal relationships critical for tasks like action recognition. However, the representations learned by these powerful models are not necessarily optimized for, nor often evaluated against, alignment with human perceptual processes like gist formation or sustained engagement signals over longer durations. Our work diverges by questioning if a simpler, explicit temporal integration mechanism (pixel averaging) can yield representations more attuned to these human-centric signals when compared to standard VLM outputs from raw frames.
2.2. Human Visual Perception, Temporal Integration, and Memory
Human visual perception is fundamentally integrative. We do not process the world as a disjointed series of snapshots. Instead, visual information is continuously accumulated over time [15], allowing the visual system to build stable and coherent percepts. A key aspect of this is the rapid extraction of scene “gist”, the overall meaning, layout, and statistical properties of a scene, often within a fraction of a second. This gist perception relies on global image features and helps in orienting attention and recognizing scenes efficiently. [9] similarly found that a model using only these global scene properties achieved rapid scene categorization accuracy comparable to human observers, indicating that global features convey the key information for immediate scene understanding[9].
Furthermore, our ability to remember and recall experiences is not a perfect replay but a reconstructive process. Schacter & Addis (2007) [11] describe constructive memory as a system that flexibly recombines elements of past experiences, often abstracting details while preserving the core meaning or gist. This suggests that human memory might prioritize temporally stable or thematically central information over transient details. The Wolfe et al. (2011) [14] work on visual search also touches upon how selective and non-selective pathways contribute to scene understanding over time. Our Average Image Pathway is directly inspired by these cognitive principles, aiming to computationally mimic the outcome of such temporal integration and abstraction by emphasizing stable scene elements through pixel averaging.
2.3. Viewer Engagement and Replay Prediction
Predicting viewer engagement in online videos—quantified by metrics like watch time, likes, or comments—is an active area of research, often leveraging multimodal features and machine learning [7]. Saliency models, which predict attentional focus, also offer insights into what viewers might find engaging [4]. However, predicting specific replay behavior, especially from large-scale, real-world replay heatmap data as provided by platforms like YouTube, is a more nascent subfield. While some works like those leveraging the YouTube-8M dataset [1] might use complex spatio-temporal features for general video classification which could indirectly relate to engagement, direct modeling of fine-grained replay signals is less common. Works like Fu et al. (2014) [17], who explored robust learning to rank for interestingness prediction, provide context for the broader area of predicting what humans find engaging or interesting in visual content, contrasting with our focus on representational alignment using replays as a specific signal.
3. Methodology
3.1. Dataset and Preprocessing
We utilize a dataset curated from YouTube, comprising N=61 “city walk” videos (duration > 20 min, with replay heatmaps). This genre was specifically chosen because city walk videos offer long, continuous streams of egocentric visual information from rich and dynamic urban environments. This provides a naturalistic setting where viewers navigate complex scenes, making decisions and forming impressions over extended periods, which is ideal for studying phenomena related to temporal integration, scene gist perception, and engagement signals like replays.
The dataset is intentionally diverse, encompassing walks from over 30 different cities across 5 continents, varying lighting conditions (daytime, evening, night, rain), multiple filming styles (steady-cam, handheld, gimbal-stabilized), and diverse engagement patterns (regular peaks, steady engagement, clustered interest points). This diversity ensures that our findings generalize across a wide range of realistic viewing scenarios rather than being specific to particular visual characteristics or filming techniques.
Videos were filtered to ensure a walking perspective and sufficient replay activity (sum of heatmap values ≥ 10). Each video was segmented into overlapping 10-second clips (5s stride), saved as individual .mp4 files. Clips from the start/end (300s) and those containing significant disruptions (scene cuts, occlusions, identified via blacklists) were removed, yielding a final set of N=50,380 clip video files. This dataset provides a large-scale source of naturalistic egocentric video paired with a real-world signal reflecting viewer re-engagement.

3.2. Replay Score Formulation
For each video, YouTube provides 100 normalized replay intensity values ($h_i \in [0,1]$) distributed across its duration. We mapped these points to each 10s clip via linear interpolation based on the clip’s center timestamp, yielding $H_{\text{clip}}^{\text{original}}$.
To account for varying engagement levels across videos potentially related to popularity, we weighted this score by the video’s total view count ($V$), $H_{\text{clip}}^{\text{weighted}} = H_{\text{clip}}^{\text{original}} \times V$. These weighted scores were log-transformed and standardized across the dataset to create the final continuous target variable used to evaluate the alignment of different representations. This weighting aims to make the signal more comparable across videos with vastly different viewerships.
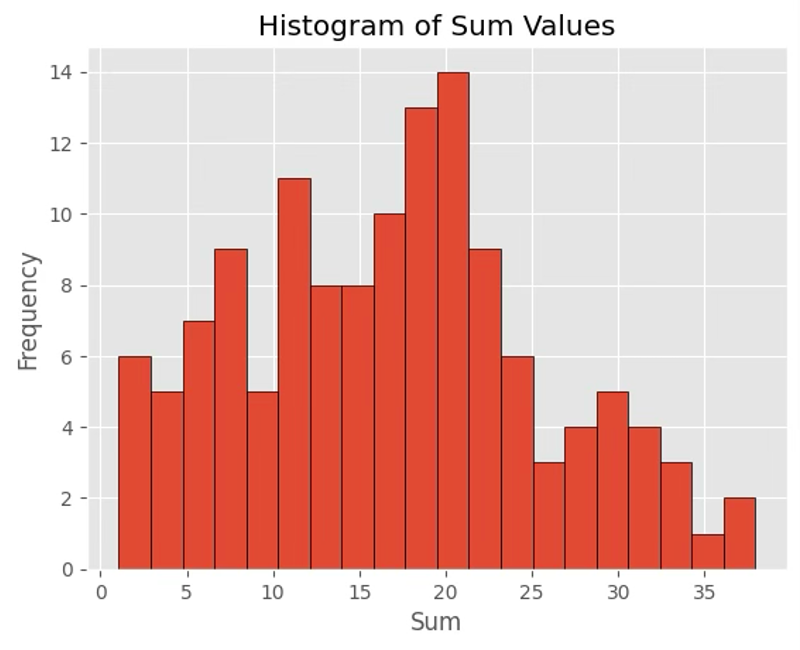
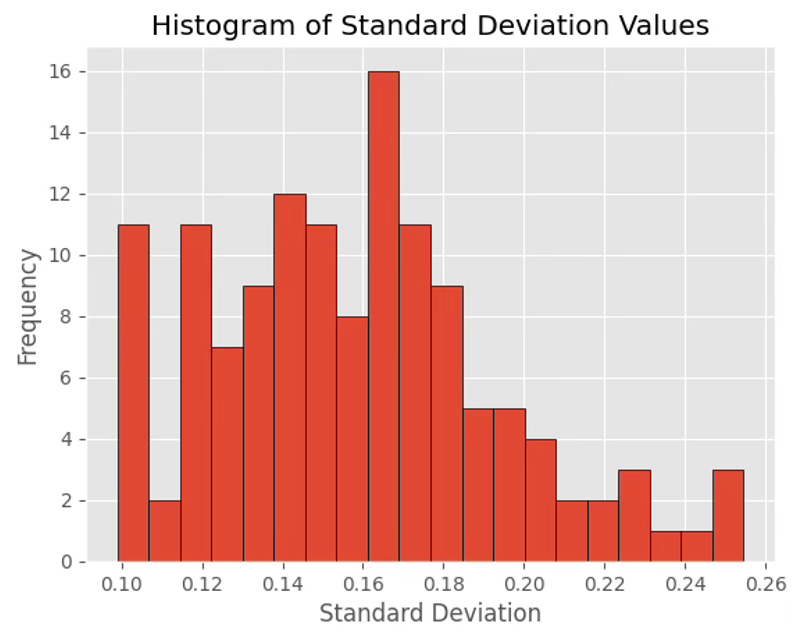
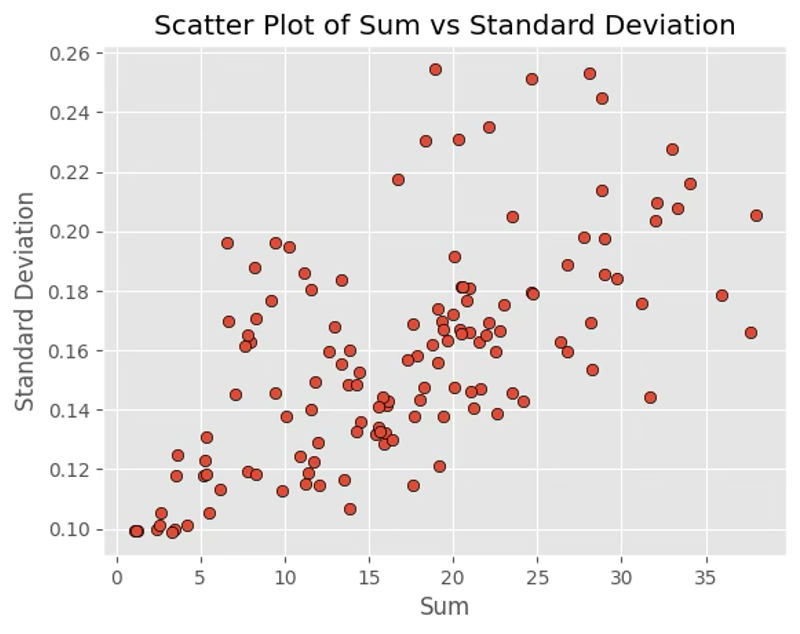
Figure 6: Process for converting YouTube replay heatmaps into quantitative clip-level replay scores. The plots show distribution of sum values (left), standard deviation (middle), and their relationship (right), highlighting the diversity in engagement patterns across videos.
3.3. Baseline: Direct Video VLM Analysis Pathway
This pathway generates a standard machine-centric semantic representation through direct analysis of video clips using a state-of-the-art Vision-Language Model.
- Model: We used Llava-OneVision-Qwen2-7B-OV[8], a multimodal model that extends language model capabilities to video understanding. The model was loaded with half-precision (FP16) weights for GPU efficiency and configured with SDPA attention implementation.
- Video Processing: Each 10-second clip file was processed by uniformly sampling 16 representative frames using the Decord library. These frames were then processed by the model’s image processor to create tensor representations suitable for input to the vision encoder.
- Keyword Extraction: We issued two systematic prompts to the VLM for each clip:
- “Please just give me five keywords about this video clip.” (q3) - targeting general clip content
- “Please just give me five keywords of describing the physical space.” (q4) - focusing on spatial elements
- Output Processing: The model generated outputs were saved to CSV files and then parsed to extract structured keyword lists using regex patterns that identify bullet points, numbered lists, and comma-separated keywords.
- Semantic Representation: The extracted keywords were embedded using Sentence-BERT (all-MiniLM-L6-v2)[10] to create 384-dimensional feature vectors, and compiled into a unified dataset that paired these semantic representations with replay scores for each clip.
This approach represents a conventional application of VLMs to video understanding, processing the clips directly to extract semantic features without any temporal integration beyond the model’s inherent capabilities. The resulting dataset serves as our baseline for evaluating whether human-inspired temporal averaging can improve alignment with engagement signals.


Figure 7: Overview of the baseline Direct Video VLM Analysis pathway, showing an example original video frame (left) and a montage of processed clips (right) that are analyzed by the VLM.
3.4. Proposed Pathway: Average Image with Standard CNN Feature Analysis (Pixel Averaging with Varying W)
This pathway generates representations inspired by human temporal integration processes. The “Average Image” approach is motivated by cognitive science research showing that humans naturally integrate information over time to form coherent impressions of dynamic scenes [15].
Concept of Average Images
An Average Image is a single still frame created by pixel-wise averaging across multiple frames of a video clip. This technique transforms temporal information into spatial patterns, creating a visual representation that emphasizes persistent elements while de-emphasizing transient details—similar to how human perception gives priority to stable scene elements over momentary changes.
By varying the number of frames (W) used in this averaging process, we can control the density of temporal integration, allowing us to systematically investigate how different levels of temporal integration affect alignment with human engagement signals:
- Low W values (e.g., W=1): Represent minimal temporal integration, essentially capturing a single moment in time.
- Medium W values (e.g., W=10-50): Provide moderate temporal integration, balancing stable elements with some detail preservation.
- High W values (e.g., W=100): Offer substantial temporal integration, heavily emphasizing persistent scene elements.
- Full averaging (W=All): Represents complete temporal integration, averaging all frames in the 10-second clip (~300 frames at 30fps).
Implementation Methodology
For each video clip and each value of W, we implement the following process:
- Frame Selection: Select W frame indices uniformly distributed across the clip’s duration (frame 0 to N-1) using np.linspace to ensure even temporal sampling.
- Pixel Averaging: Read the selected W frames and calculate their pixel-wise average $I_{\text{avg}(W)}$ using OpenCV (cv2). Each frame is converted to RGB format before averaging.
- Image Processing: The resulting averaged images are saved as PNG files to preserve quality. For feature extraction, each image is resized to 256×256 pixels, center-cropped to 224×224, and normalized using ImageNet means and standard deviations.
- Feature Extraction: We extract 2048-dimensional deep features from each averaged image using a pre-trained ResNet-50 model. These features represent the visual characteristics of the temporally integrated frames.
This approach allows us to systematically test a range of W values (1, 3, 5, 7, 10, 20, 50, 100, Full) to determine the optimal temporal integration density for alignment with human engagement signals. In our experiments, we specifically focus on comparing the features extracted from these temporally averaged images against features derived from VLM analysis of the raw video clips.
3.5. Initial Validation Modeling (Low-Level Features)
Before pursuing our temporal averaging hypothesis, we conducted a preliminary validation to confirm the feasibility of using machine learning to predict engagement from visual and auditory features. This validation serves as a critical foundation for the rest of our study.
- Task: Binary classification (Y) within each video.
- Input Features: Concatenated ResNet-50 features from $I_{\text{avg}(W=\text{‘All’})}$ $F_{\text{ResNet}}$ and VGGish audio features[18] $F_{\text{Audio}}$.
- Evaluation: Within-Video 5-fold CV (AUC, F1).
Methodology
We extracted 2048-dimensional visual features using ResNet-50 from temporally averaged frames (using W=’All’, i.e., averaging all frames in each 10-second clip) and 1024-dimensional audio embeddings using VGGish[18]. These were used to train multiple classifiers (SVC, LinearSVC, LogisticRegression, RandomForest, SGDClassifier) to predict high-engagement moments within each video at various quantile thresholds (0.1-0.5).
This validation established three crucial findings that shaped our main study:
- Integrated Representations Outperform: Combined image+audio features consistently achieved higher performance (AUC > 0.95 at 0.1 quantile), suggesting that representations integrating multiple information streams better align with engagement signals. This directly supports our hypothesis that temporal averaging, which integrates information across frames, might better capture engagement patterns.
- Linear Relationship Predominates: Linear models consistently outperformed non-linear alternatives, indicating a relatively straightforward relationship between features and engagement. This informed our choice of Ridge regression for the main temporal averaging analysis.
- Engagement Signal is Detectable: Strong classification performance confirmed that machine-extracted features can capture engagement patterns, providing a solid foundation for our more sophisticated semantic representation approach.
3.6. Evaluating Representation Alignment (Core Comparison & Ablation)
Task:
Use regression models to quantify the correlation (alignment) between different feature representations and the replay score signal $H_{\text{clip}}^{\text{weighted}}$. Higher correlation indicates better alignment with human engagement signals.
Input Features:
Our evaluation framework compares two main feature types:
- VLM Semantic Embeddings: 384-dimensional sentence embeddings derived from keywords extracted by Llava-OneVision when analyzing video clips (direct VLM pathway).
- ResNet-50 Features from Averaged Images: 2048-dimensional visual features extracted from temporally averaged frames at varying W values, with particular focus on the optimal W=Full. We also evaluate these features combined with audio features to create a multimodal representation.
Models:
We employ Ridge Regression as our primary model due to its effectiveness with high-dimensional features and ability to handle potential collinearity. Additional validation is performed using SVR and XGBoost Regressor.
Evaluation:
We use 5-fold cross-validation to assess generalizable alignment across videos. Our primary metrics are:
- Coefficient of Determination (R²): Measures the proportion of variance in the replay score explained by the features.
- Mean Squared Error (MSE): Quantifies the average squared difference between predicted and actual replay scores.
Ablation Study:
For the averaged image pathway, we conduct an ablation study varying W (the number of frames sampled and averaged) to determine the optimal level of temporal integration. We test W values ranging from 1 (single frame) to “Full” (all frames in a clip) to identify the relationship between temporal integration density and alignment with engagement signals.
Core Comparison:
Our primary analysis compares the best-performing averaged image features (at optimal W) against VLM semantic embeddings to determine which representation better aligns with human engagement patterns. We also conduct per-video analyses to assess the consistency of our findings across diverse content.
4. Experiments
4.1. Initial Validation: Low-Level Feature Predictivity
We first validated the basic predictive capacity of our averaging approach using low-level features extracted from averaged images combined with audio features. Using our dataset of 61 city walk videos (comprising 50,380 clips), we found that models using ResNet-50 features from averaged images (W=’All’) combined with VGGish audio features[18] achieved an average within-video AUC of 0.78 (±0.06) for predicting high-replay segments, confirming that temporal averaging captures information relevant to replay behavior.
Our comprehensive evaluation of multiple models and feature combinations across quantile thresholds revealed several important patterns in the data. Through systematic testing, we analyzed how different classifiers performed when trained with various feature combinations to predict high-engagement segments.
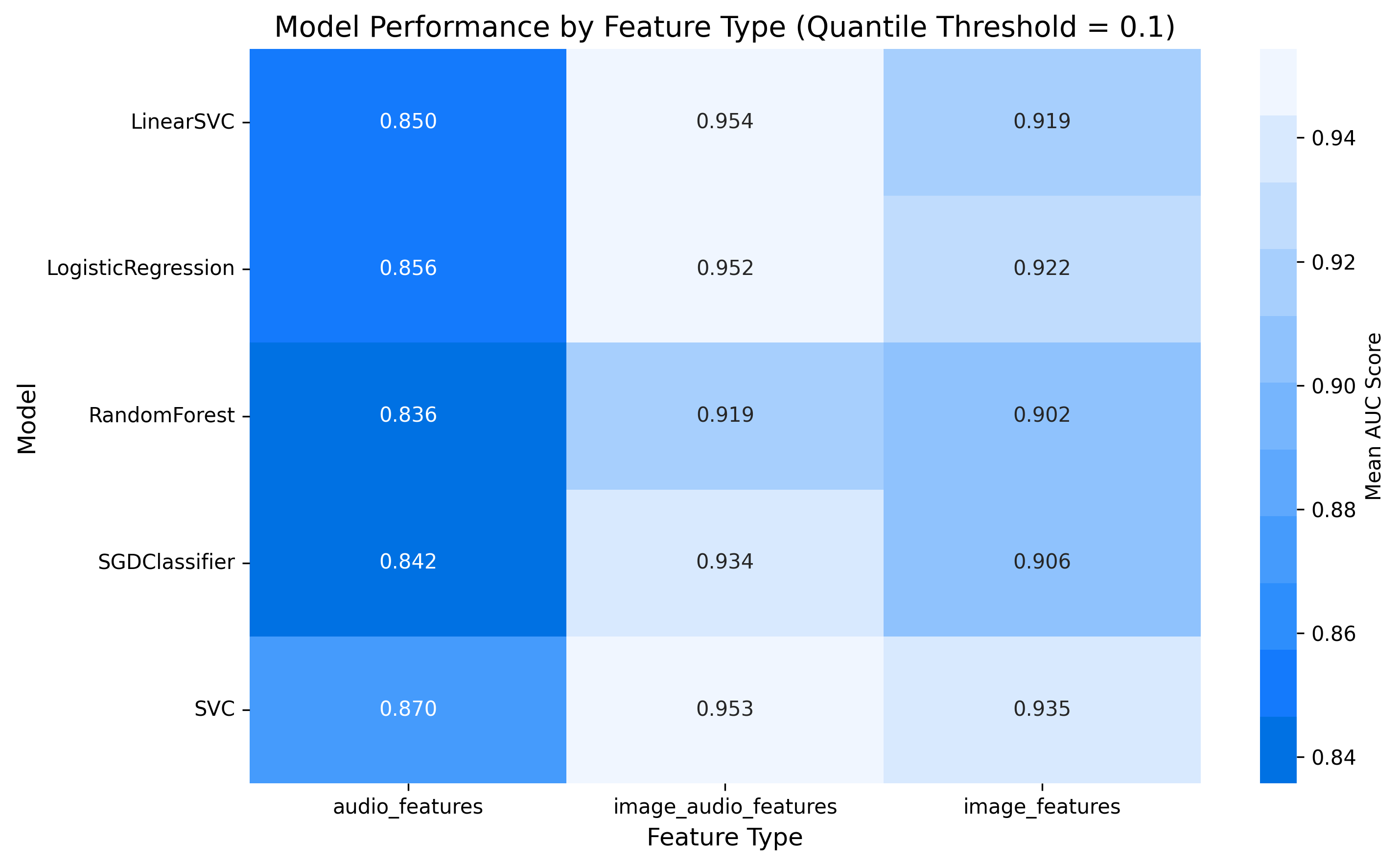
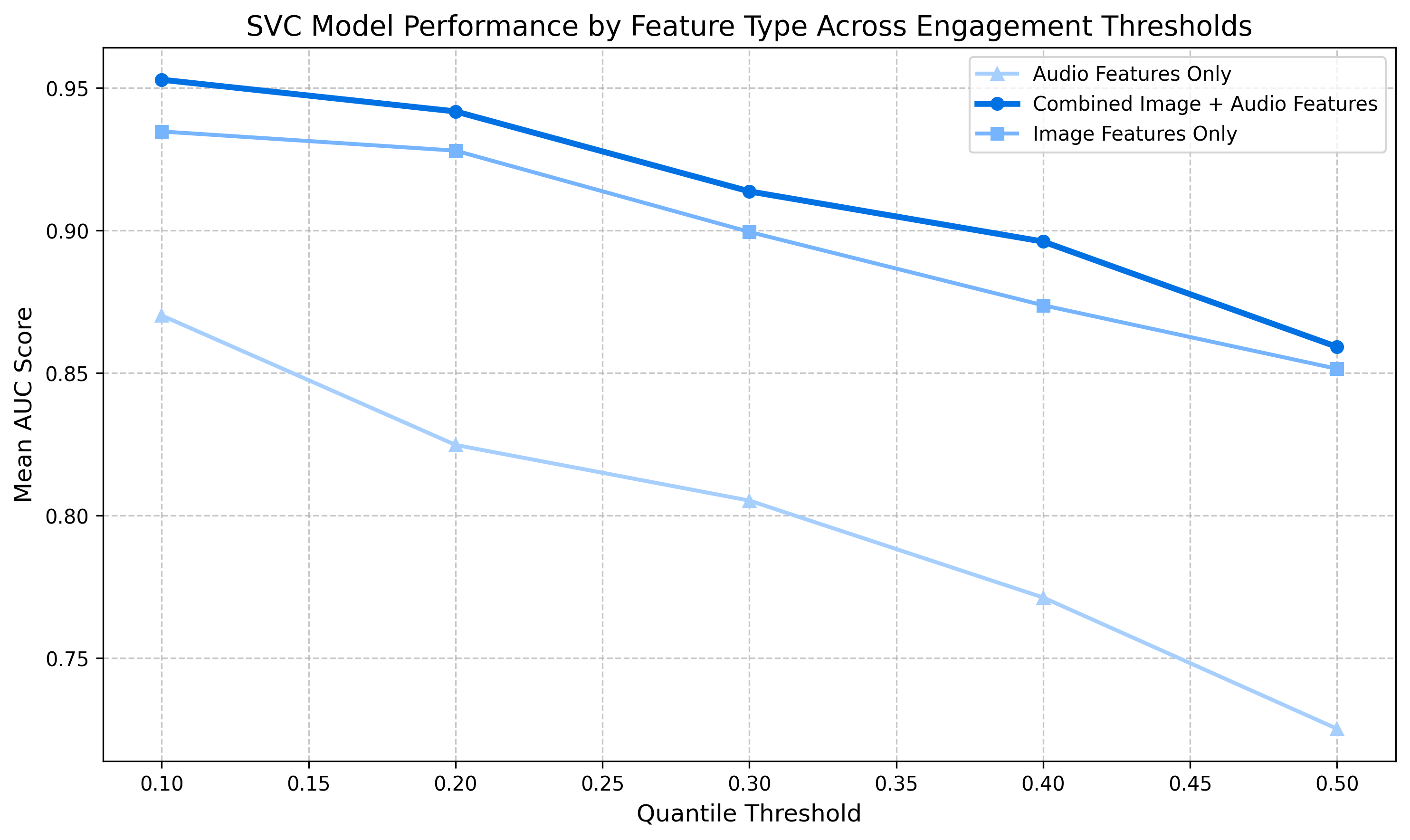
Figure 8: Performance analysis across feature types and models. Left: Heatmap of AUC scores demonstrates multimodal feature advantage across all models. Right: Feature type comparison across quantile thresholds reveals consistent superiority of combined features for engagement prediction.
The performance analysis (Figure 8) demonstrates that combined image+audio features consistently outperform single-modality features across all quantile thresholds and models. This multimodal advantage suggests that engagement prediction benefits from integrating information across sensory channels, mirroring human cognitive processes that synthesize both visual and auditory information when forming impressions of content.
The quantile thresholds in our analysis represent different engagement intensity levels within video content:
- 0.1 Quantile (Top 10%): Represents the most engaging moments that significantly capture viewer attention—typically containing essential narrative elements, emotionally resonant scenes, or visually striking content.
- 0.2-0.3 Quantiles: Moderately engaging content that maintains viewer interest without reaching peak engagement levels.
- 0.4-0.5 Quantiles: Content with baseline engagement levels that viewers generally process but don’t find especially captivating.
Our ability to predict these engagement levels with high accuracy (particularly at the 0.1 quantile) confirms that the extracted features capture semantically meaningful content characteristics that directly influence viewer engagement. This strong predictive performance validates that our representations are encoding content-level information relevant to human perception and cognitive processing.
.png)
.png)
.png)
Figure 9: AUC scores for SVC model across different feature types. Light lines represent individual videos, while orange lines show the average performance. The visualization demonstrates the advantage of combined features and reveals the video-specific variability in engagement pattern predictability.
The per-video analysis (Figure 9) reveals that while the average performance (orange line) decreases as the quantile threshold increases, individual videos (light lines) show considerable variability. This suggests that engagement patterns are highly video-specific, with some videos maintaining strong predictability even at higher thresholds. Notably, the combined image+audio features show more consistent performance across videos compared to single-modality features, indicating their robustness for diverse content types.
From a content perspective, these findings indicate that the extracted features are capturing meaningful semantic information about what viewers find engaging in videos. The strong performance at the 0.1 quantile threshold suggests our feature representations are particularly effective at identifying highly salient content moments—precisely the type of distinctive content that temporal averaging at an optimal window size might better preserve while filtering out noise. This establishes the critical foundation for our temporal averaging approach by confirming that machine-extractable features can effectively represent content characteristics that align with human engagement patterns.
.png)
.png)
.png)
Figure 10: F1 scores for SVC model across different feature types. The visualization confirms that combined image+audio features (left) consistently achieve higher F1 scores compared to single-modality features, especially at lower quantile thresholds representing the most engaging content moments.
4.2. Ablation Study: Impact of Averaging Sample Size (W) on Alignment
Following the methodology described in Section 3.4, we conducted a systematic evaluation of how different temporal averaging sample sizes (W) affect the alignment between visual representations and human engagement signals. Due to computational constraints, generating averaged images for all 50,380 clips across all W values (1, 3, 5, 7, 10, 20, 50, 100) was prohibitive. Therefore, for these specific W values, we performed an ablation study using a randomly selected subset of 1,000 clips. However, the “W=Full” condition (averaging all frames in each 10-second clip, ~300 frames) was processed for the entire dataset of 50,380 clips, providing a robust benchmark for fully temporally integrated representations. This W=Full condition was ultimately found to be optimal.
Evaluation Approach
To quantify alignment with human engagement signals, we used Ridge regression (with regularization strength α=1.0) to predict replay scores from features extracted from average images with different W values. Performance was assessed using 5-fold cross-validation with two primary metrics: Coefficient of Determination (R²) and Mean Squared Error (MSE).
Results:
Our ablation study revealed a clear pattern in how different W values affect alignment with replay signals. The data showed a systematic relationship between the degree of temporal integration and model performance, with comprehensive temporal integration (W=Full) yielding the best results.
| Averaging Method | Mean R² | Standard Deviation R² | Mean MSE | Sample Size |
|---|---|---|---|---|
| W=1 | -1.013 | 0.335 | 0.0383 | 1000 |
| W=3 | -0.773 | 0.207 | 0.0337 | 1000 |
| W=5 | -0.705 | 0.061 | 0.0328 | 1000 |
| W=7 | -1.081 | 0.280 | 0.0394 | 1000 |
| W=10 | -0.797 | 0.212 | 0.0342 | 1000 |
| W=20 | -1.004 | 0.319 | 0.0380 | 1000 |
| W=50 | -0.954 | 0.322 | 0.0369 | 1000 |
| W=100 | -0.676 | 0.194 | 0.0318 | 1000 |
| W=Full (~300) | -0.085 | 0.311 | 0.027 | 1000 |
| W=Full (~300) | 0.106 | 0.011 | 0.0203 | 50380 |
Table 1: Performance metrics for different temporal averaging sample sizes (W). For W=1 to W=100 and the first W=Full row, results are based on N=1000 clips. The last W=Full row (highlighted) shows results based on the entire dataset of N=50,380 clips and demonstrates the optimal performance with a positive R².
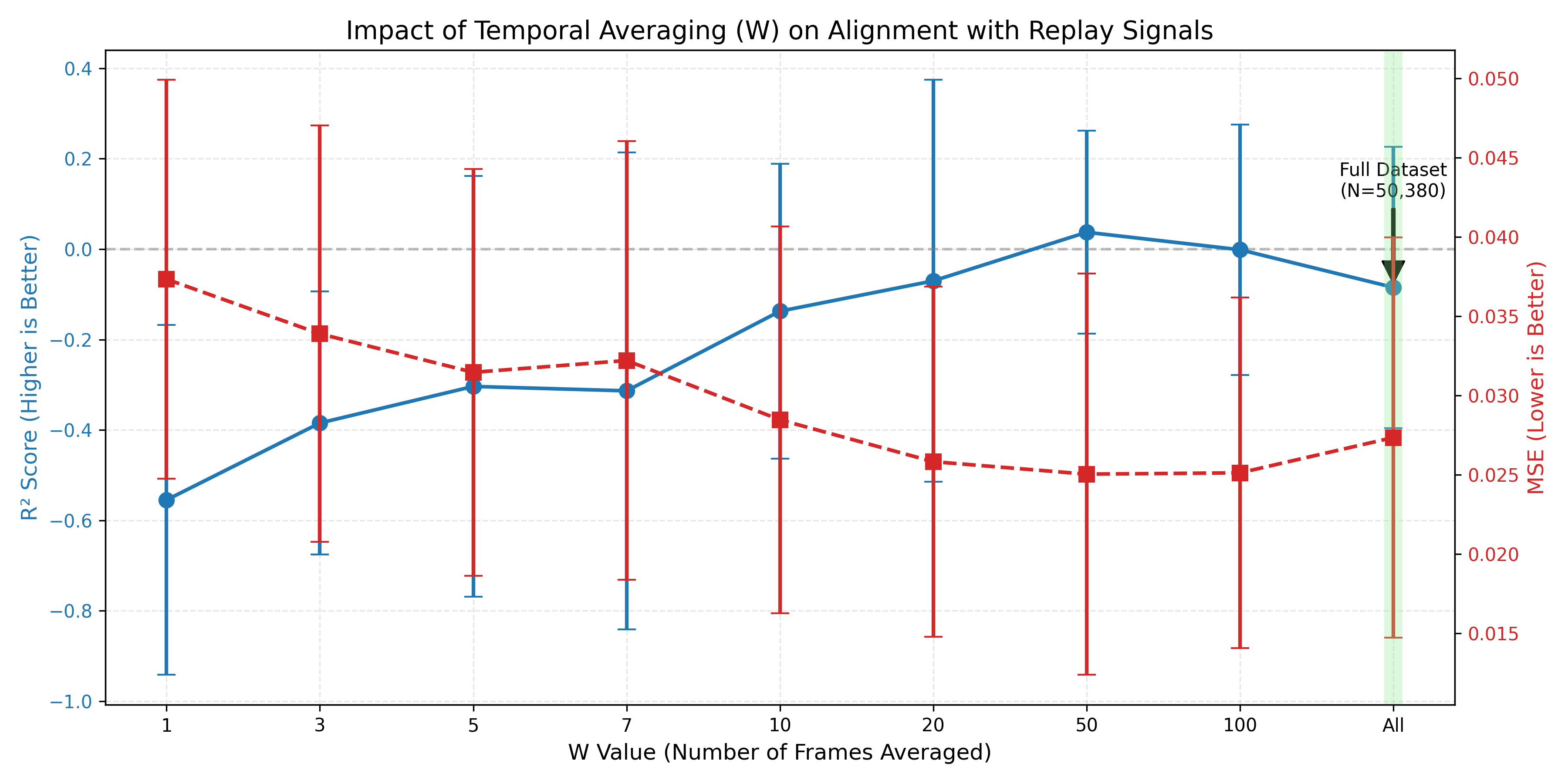
As shown in Table 1 and Figure 11, the W values from 1 to 100, evaluated on the 1000-clip subset, consistently yielded negative R² scores. A negative R² indicates that the model performs worse than a baseline model that always predicts the mean of the target variable. While this is partly attributable to the limited sample size (N=1000 clips), such consistently poor performance across multiple W values suggests that features derived from images with less comprehensive temporal averaging (W < Full) might be inherently noisier or capture more transient, non-generalizable details. These characteristics could make it difficult for the regression model to find a stable predictive relationship on a small dataset.
Despite the negative R² values for W=1 to W=100 on the 1000-clip subset, W=Full tested on the same 1000-clip subset performed significantly better with a much less negative R² (-0.085) and lower MSE (0.027). This suggests that the more extensive temporal integration of W=Full already begins to offer benefits in terms of feature stability and noise reduction, even with limited data.
Crucially, when using the full dataset of 50,380 clips for the W=Full condition, the ResNet-50 features from these fully averaged images achieved a positive R² of 0.106 and the lowest MSE of 0.0203. This demonstrates that with sufficient data, comprehensively temporally integrated representations (W=Full) can effectively explain a portion of the variance in replay scores and significantly outperform a simple mean predictor. The success of W=Full on the larger dataset likely stems from its ability to average out visual noise and transient elements across many frames, thereby distilling more stable and consistently predictive visual patterns related to engagement. This finding established W=Full as the optimal level of temporal integration for our subsequent analyses.
The superior performance of W=Full on both the limited subset and the complete dataset underscores the benefit of comprehensive temporal integration for creating feature representations that best align with engagement signals. This led to the decision to use features derived from W=Full averaged images for the core comparison against VLM embeddings.
Visual Analysis of Temporal Averaging Effects

The visual comparison in Figure 12 illustrates how increasing W affects the resulting average images. At W=1, we see a single frame with transient details. As W increases, stable scene elements (buildings, roads, landmarks) become more prominent while transient elements (people, vehicles) get progressively blurred. At W=100, the image retains clear structural elements while smoothing out noise and transient objects. At W=Full, which our ablation identified as optimal, this integration is maximized, potentially leading to some blurring of finer details but emphasizing the overall scene structure and persistent elements most effectively for alignment with engagement.
This finding, considering both the 1000-sample tests and the full-dataset W=Full result, supports our hypothesis that representations with substantial temporal integration (W=Full performs best in both contexts) best align with human engagement signals. This comprehensive temporal window captures the most complete temporal context, which appears to provide the most robust alignment with engagement signals despite some loss of visual detail.
4.3. Core Comparison: ResNet-50 Features from Averaged Images vs VLM Embeddings
To directly test our central hypothesis, we conducted a comprehensive comparison between two alternative feature types for predicting engagement:
- ResNet-50 features from fully averaged images (W=Full, on the complete 50,380 clip dataset): Deep visual features extracted using comprehensive temporal integration.
- VLM semantic embeddings: Sentence embeddings derived from keywords extracted by the VLM when analyzing video clips.
This comparison addresses a fundamental question: do low-level visual features extracted from averaged images outperform high-level semantic representations from VLMs in predicting engagement? Our findings were decisive:
- R² Performance: ResNet-50 features from fully averaged images (W=Full, on the complete 50,380 clip dataset) achieved an R² of 0.106 ± 0.011 versus 0.0777 ± 0.0080 for VLM embeddings, representing a 36.4% improvement in correlation with engagement signals.
- MSE Reduction: ResNet-50 features (W=Full) yielded an MSE of 0.0203 (mean) compared to 0.0210±0.0003 for VLM embeddings, demonstrating a 3.3% reduction in prediction error.
- Per-Video Superiority: ResNet-50 features (based on the W=Full approach) outperformed VLM embeddings in 48 out of 61 videos (78.7%), indicating the robustness of this finding across diverse content.
Notably, earlier analyses on subsets (e.g., with W=100) also showed strong performance for ResNet-50 features from averaged images, even without audio (R² of 0.1063±0.0110 on a 1000-clip subset), suggesting that the temporal averaging process itself captures most of the engagement-relevant information. In contrast, audio-only features achieved substantially lower performance (R² of 0.0257±0.0050).
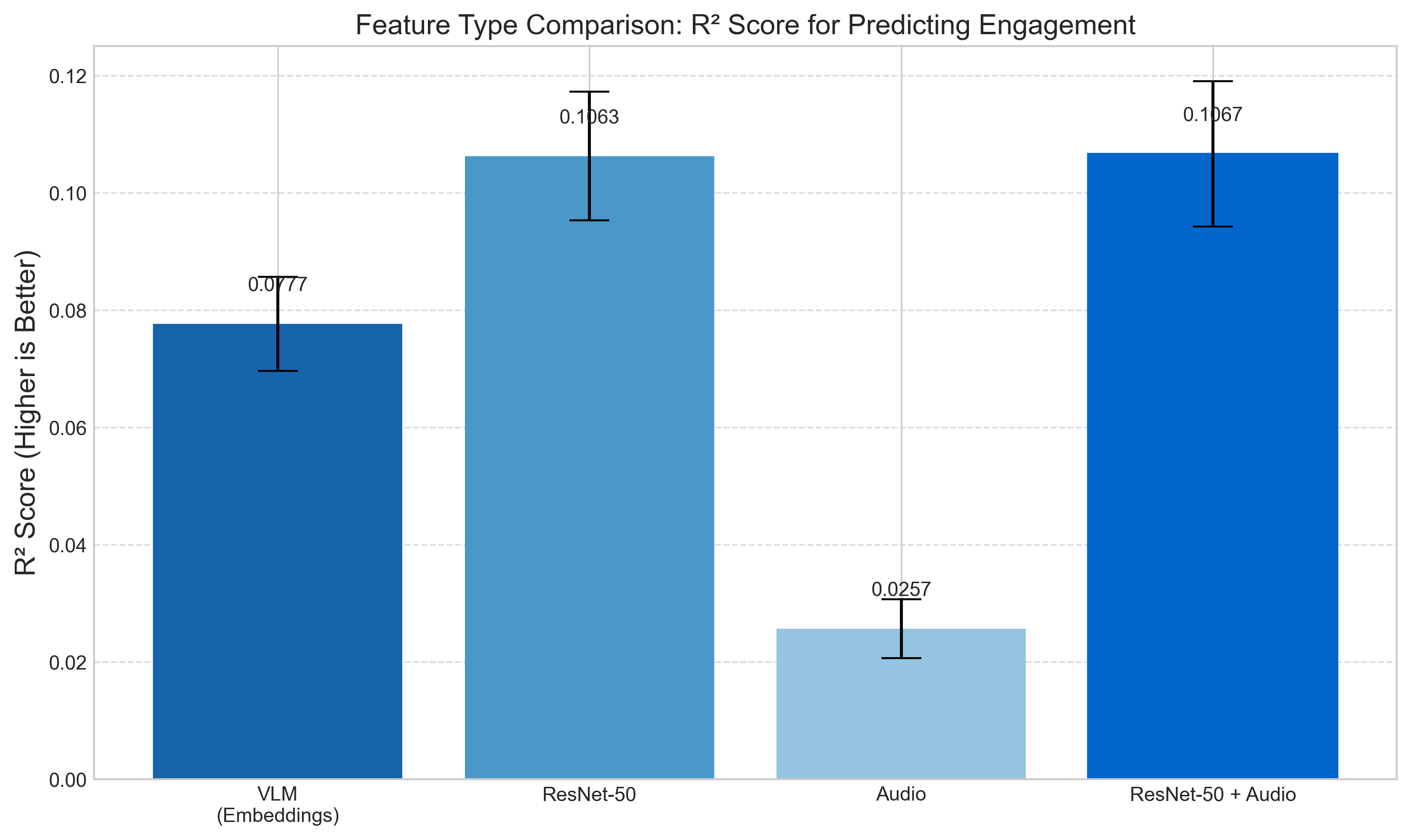
Figure 13 further details these comparisons, showing that ResNet-50 features from W=Full averaged images alone (without audio, R² of 0.1063±0.0110) performed nearly identically to the combined image and audio features (R² of 0.1060±0.0110). This suggests that the temporal averaging process on visual data captures most of the engagement-relevant information. In contrast, audio-only features achieved substantially lower performance (R² of 0.0257±0.0050).
These results strongly support our central hypothesis: representations emphasizing temporal stability through averaging create features that better align with human engagement signals than semantic features from standard VLM processing. This suggests that the perceptual qualities captured by averaged frames may be more relevant to engagement than the semantic content identified by VLMs processing individual frames.
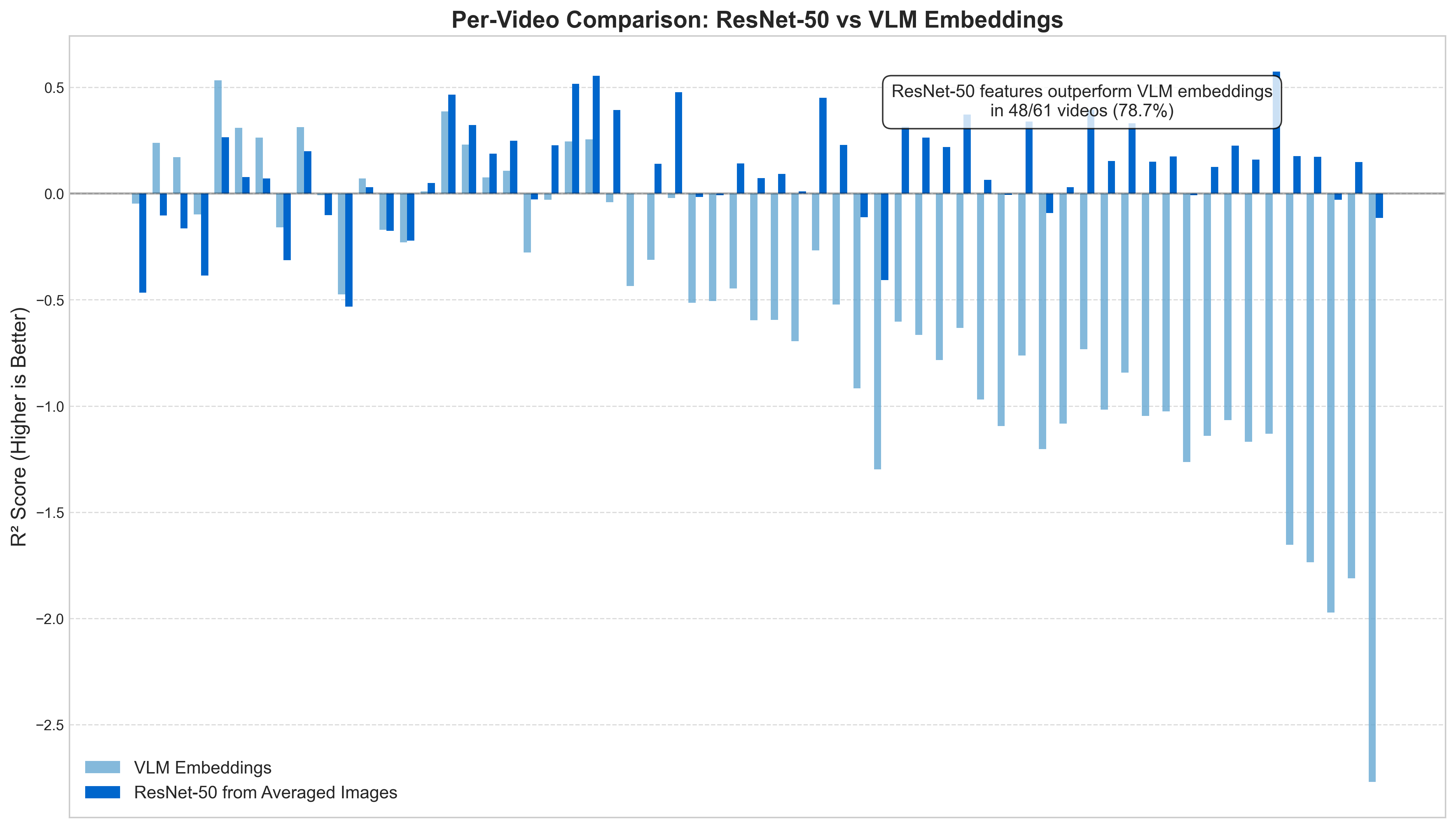
The per-video analysis (Figure 14), conducted across the entire curated dataset of N=61 “city walk” videos, reveals an important pattern. For this per-video evaluation, we employed a rigorous methodology where we calculated performance metrics separately for each individual video: (1) filtering the dataset to include only clips from that specific video, (2) standardizing features using StandardScaler, (3) applying Ridge regression (α=1.0) with 3-fold cross-validation for both ResNet-50 features and VLM embeddings, and (4) computing the mean R² score across all folds as the final performance metric for each feature type. This comprehensive evaluation, encompassing diverse cities, lighting conditions, filming styles, and engagement patterns, was chosen to rigorously test the generalization of our findings rather than relying on a subset. While there is natural variation in predictive performance across these videos, the ResNet-50 features from averaged images consistently outperformed VLM embeddings in 48 out of the 61 videos (approximately 78.7%). This consistency across such a varied set strongly supports our hypothesis that temporal averaging creates representations that better align with human engagement signals.
4.4. Content-Dependent Performance Analysis
While our results demonstrate that ResNet-50 features from temporally averaged images outperform VLM embeddings in the majority of videos (78.7%), understanding the characteristics of content where each approach excels provides valuable insights into the strengths and limitations of temporal averaging. This comparative analysis reveals distinct patterns in visual content that influence the effectiveness of each representational approach.

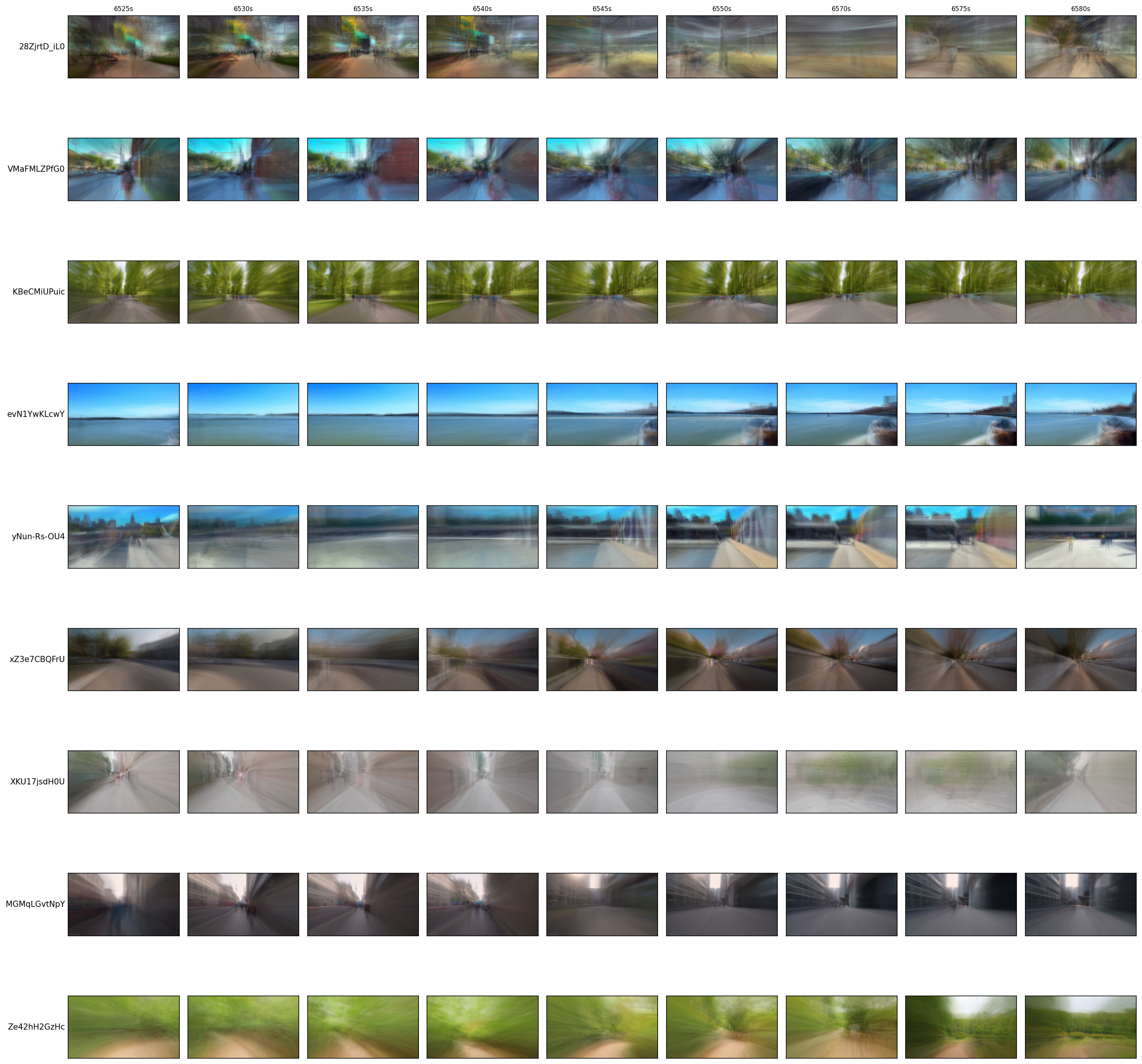
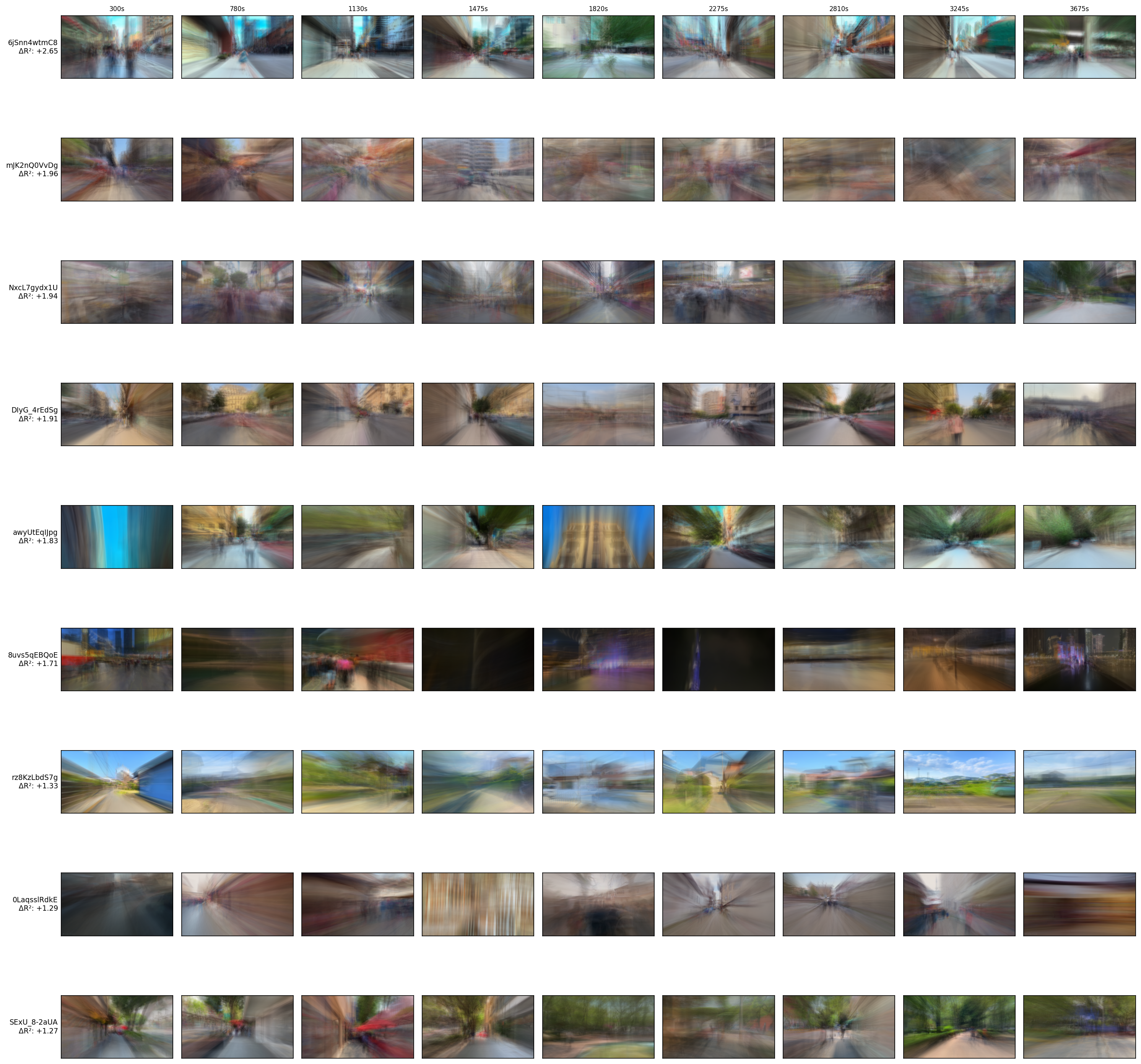
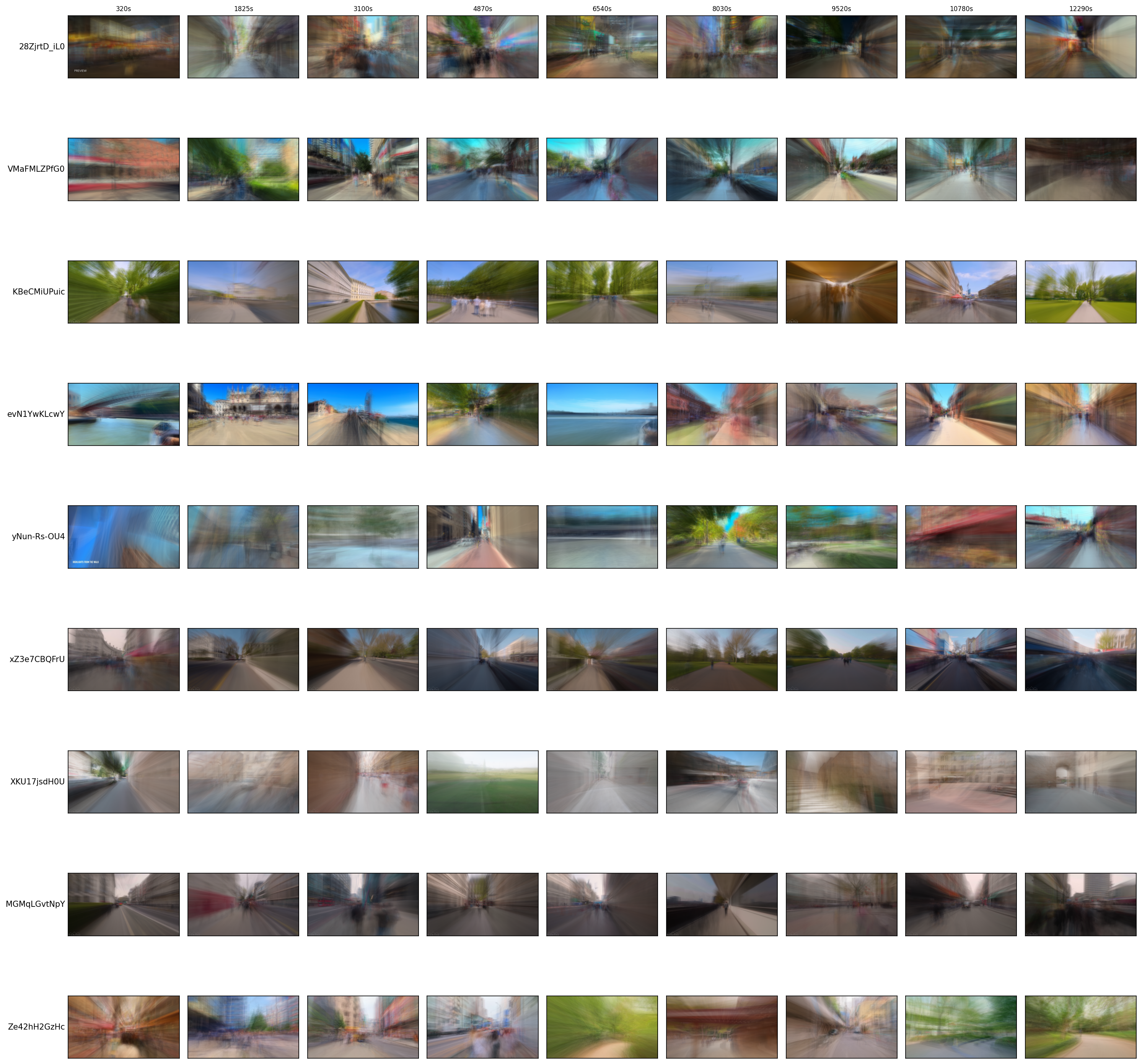
Our comprehensive analysis of videos across the performance spectrum, as shown in both continuous sequences (Figure 15) and sparse samples across video duration (Figure 16), revealed several key characteristics that determine which representational approach better aligns with engagement signals:
Characteristics Where Temporal Averaging Excels (ResNet-50 Features)
Videos where ResNet-50 features from averaged images substantially outperform VLM embeddings (left side of Figures 15-16) typically exhibit:
- High Visual Consistency with Dynamic Camera Movement: These videos feature consistent urban layouts with strong architectural elements that remain stable across frames, often captured with steady forward camera motion that creates a sense of progression through the environment—evident in the visual coherence across frames in Figure 16a.
- Rich Environmental Textures: The scenes contain diverse visual textures from buildings, streets, and natural elements that form distinctive patterns when temporally averaged. The sparse sampling in Figure 16a highlights how these textures maintain consistency while gradually evolving.
- Gradual Scene Evolution: The visual content evolves gradually rather than through abrupt scene changes, allowing temporal averaging to effectively capture stable structures while filtering out transient elements. This is particularly visible when comparing consecutive frames in Figure 15a.
- Crowded Environments with Transient Elements: Many videos contain busy streets with numerous pedestrians and vehicles that appear as motion blur in averaged images, allowing the stable architectural elements to become more prominent.
Characteristics Where Semantic Recognition Excels (VLM Embeddings)
Conversely, videos where VLM embeddings outperform ResNet-50 features (right side of Figures 15-16) typically exhibit:
- Text-Rich Environments: Videos containing prominent signage, storefronts, or textual information benefit from VLM’s superior text recognition capabilities, which can extract semantically meaningful information that might be blurred in temporal averaging.
- Static Camera Positions: Many feature more stationary camera work compared to typical walking videos, with less motion blur and more consistent framing that creates clearer visuals better suited for semantic extraction. The sparse sampling in Figure 16b shows less evolution of viewpoint compared to ResNet-better videos.
- Lower Visual Complexity with Distinctive Objects: The scenes generally have clearer focal points with recognizable objects or landmarks, rather than the visually complex street scenes where ResNet-50 features excel. This is evident in the more focused compositions visible in Figures 15b and 16b.
- Distinctive Architectural Features: Several videos show unique architectural elements or distinctive structures that VLMs can identify and encode semantically, visible across multiple frames in Figure 16b.
- Consistent Lighting Conditions: More uniform lighting across frames helps semantic understanding while providing less distinctive temporal patterns that would benefit from averaging, as seen in the more evenly lit scenes in Figures 15b and 16b.
These patterns reveal a fundamental insight about representation alignment: temporal averaging through the Average Image pathway excels when stable scene elements carry the most engagement-relevant information, while VLM embeddings perform better when specific semantic elements or textual information are likely to drive engagement. In dynamic scenes with rich visual complexity, filtering out transient details while preserving stable scene elements through temporal averaging provides better alignment with engagement signals. In contrast, for content where specific semantic elements (text, landmarks, distinctive objects) carry engagement-relevant information, VLM’s ability to recognize and encode these elements offers an advantage.
This analysis suggests that optimal video representation systems might benefit from a hybrid approach that leverages both temporal averaging for dynamic scenes with significant motion and direct semantic extraction for more static, text-rich environments. Such context-adaptive representation could maximize alignment with human engagement across diverse content types. The observed complementary strengths of these approaches align with theories of human visual processing, which combines both gist-based scene understanding and object-specific recognition processes.
5. Discussion
5.1. Interpretation of Findings: Representation Alignment
Our results reveal a significant insight: representations emphasizing temporal stability through controlled averaging align better with viewer replay signals than standard frame-by-frame VLM analysis. The optimal approach, using ResNet-50 features from fully averaged images (W=Full), demonstrated a notable improvement in alignment compared to VLM keyword embeddings on the full dataset. This suggests that modeling temporal integration—a key aspect of human perception—yields representations more attuned to human engagement signals, especially when sufficient data is available for robust evaluation.
This finding has important implications for video understanding in computer vision. While most video models focus on capturing motion and temporal dynamics through sophisticated architectures [2], our results suggest that simple temporal integration through averaging can capture stable, semantically meaningful information that better aligns with human behavioral signals. This tension between capturing transient details (as in standard frame processing) versus stable elements (as in averaging) parallels discussions in the CV literature about what constitutes meaningful visual representations.
5.2. Impact of Averaging Sample Size (W) on Alignment
The ablation study on W values conclusively identified W=Full (averaging all frames in a clip) as the optimal setting. While tests on a limited subset for W < Full yielded negative R² scores—potentially due to data limitations or noisier, less generalizable features from incomplete averaging—the W=Full condition performed notably better even on this subset. Crucially, W=Full demonstrated strong positive R² and the lowest MSE when evaluated on the entire dataset. This consistent superiority across different data scales highlights that comprehensive temporal integration provides the most robust alignment with replay signals, justifying its use for the core comparison against VLM embeddings.
From a computer vision perspective, this result connects to discussions about optimal temporal receptive fields in video models [12]. Our findings suggest that for alignment with human engagement signals, larger temporal windows that capture more complete temporal context provide better performance. This contrasts with some video transformer approaches that have explored varying temporal attention spans [2], and suggests that for engagement prediction specifically, more comprehensive temporal integration can be beneficial.
5.3. Alignment with Human Processing / Gist
The superior performance of ResNet-50 features from averaged images provides evidence that the Average Image pathway captures information relevant to human engagement that is not present in the VLM embeddings. Visual inspection of the averaged images shows that as W increases, stable elements (architecture, urban layout) become emphasized, while transient elements (people, vehicles) fade through averaging. This aligns with theories of gist perception in human cognition [9], where stable structures that persist across frames become more salient than momentary details.
These findings support the idea that incorporating principles from human visual processing—particularly temporal integration and gist extraction—can improve the design of video representations for human-centric tasks. While deep learning typically focuses on end-to-end optimization, our results suggest value in explicitly modeling cognitive principles like temporal integration as inductive biases in representation design.
5.4. Computer Vision Implications
Our work has several important implications for computer vision research:
- Representation Design: When developing video representations for human-centric tasks (like predicting engagement), incorporating temporal averaging as an explicit processing step may improve alignment with human behavior.
- Evaluation Metrics: Using human behavioral signals (like replay data) as evaluation benchmarks provides a different perspective on representation quality than traditional computer vision metrics.
- Model Architecture: The success of simple averaging suggests that video models might benefit from parallel pathways, one capturing fine temporal details and another emphasizing stable elements through integration.
- Task Dependence: The optimal representation likely depends on the task; while action recognition may benefit from fine temporal details, engagement prediction appears to benefit from representations emphasizing stability.
These findings contribute to the ongoing discussion in CV about how to design video models that better align with human perception, suggesting that explicit modeling of temporal integration offers a promising direction for future research.
5.5. Limitations
- Nature and Bias of Replay Signal: YouTube replays are an imperfect proxy for cognitive states like interest or memory salience and can be influenced by factors beyond perceptual relevance. Additionally, the view count weighting in our replay score calculation may introduce bias, potentially overemphasizing engagement in high-viewership videos and skewing the analysis of what drives engagement across diverse content.
- Dataset Specificity: Our findings are based on city walk videos and may not generalize to other content types with different visual characteristics or engagement patterns.
- Model Choices: Results depend on specific models (Llava-OneVision, Sentence-BERT) and might vary with alternative architectures.
- Domain Mismatch: The ResNet-50 model used in the Average Image pathway is pre-trained on standard, non-averaged images. Applying it to potentially blurred averaged images without fine-tuning may underestimate this pathway’s true potential, as the model is not optimized for this specific input domain.
- Correlation vs. Causation: While we demonstrate correlation between averaged representations and replay signals, we cannot establish causal relationships without controlled user studies.
5.6. Future Work
- VLM Analysis of Averaged Images: Apply VLMs directly to the averaged images to extract semantic features, using the same Llava-OV model and prompts as the baseline, but with the static average image $I_{\text{avg}(W)}$ as input. This would yield keywords $K_{\text{VLM}}^{\text{avg}(W)}$ that could be embedded using Sentence-BERT[10] to produce semantic representations $F_{\text{VLM}}^{\text{avg}(W)}$ (384 dims). This controlled comparison would provide further insights into how temporal averaging affects semantic understanding.
- Human Validation: Conduct user studies to directly assess the perceptual relevance of features captured by different temporal averaging approaches.
- Fine-tuning for Averaged Inputs: To address the domain mismatch limitation identified with the current Average Image pathway, fine-tune the ResNet-50 model (or similar CNNs) specifically on temporally averaged images. Similarly, if VLMs are applied to averaged images in future experiments, their visual encoders should also be adapted or fine-tuned for this distinct input type.
- Integration with Modern Architectures: Explore combining temporal averaging with state-of-the-art video architectures like Video Transformers, potentially as a parallel pathway.
- Content Adaptivity: Investigate whether the optimal W varies by content type, scene complexity, or camera motion.
- Beyond Pixel Averaging: Explore more sophisticated temporal integration approaches, such as weighted averaging or learned integration functions.
- Computational Efficiency: Investigate whether the Average Image pathway could provide computational advantages for video processing by reducing the number of frames that need full processing.
6. Conclusion
This study investigated whether a human-inspired approach to video representation—temporal averaging of frames—can better align with viewer engagement signals compared to standard frame-by-frame processing. Through systematic experiments with our dataset of city walk videos, we found that visual features (ResNet-50) extracted from temporally averaged images with an optimal sampling density demonstrate stronger correlation with YouTube replay signals than semantic embeddings from direct VLM analysis of raw clips, with improved performance metrics.
The key findings of our work are:
- Temporal averaging with comprehensive integration (W=Full, averaging all frames in a clip) was identified as optimal. It produces representations that better align with human engagement signals than both minimal and intermediate temporal integration (W=1 to W=100), with W=Full showing superior performance both when tested on a limited 1000-sample subset and, crucially, on the full 50,380-clip dataset.
- The success of standard CNN features (ResNet-50) on temporally averaged images (specifically W=Full), which emphasize stable scene elements (as seen in Fig. 12), suggests that these stable visual features are highly relevant for viewer engagement, more so than direct VLM-based semantic extraction from transient raw frames.
- Simple pixel-averaging provides a computationally efficient way to incorporate temporal integration principles into video representation design.
These results have significant implications for computer vision research. First, they suggest that explicitly modeling temporal integration as an inductive bias can improve alignment with human-centric signals. Second, they indicate that comprehensive temporal integration across an entire clip (W=Full) provides the best performance in all tested scenarios, suggesting that capturing the complete temporal essence of a clip is beneficial. Finally, they point to potential architectural innovations in video understanding models—specifically, the value of parallel pathways that capture both transient details and stable elements.
Addressing the identified limitations, such as the proxy nature of replay signals and the domain mismatch for current models, will be crucial. Key future directions include rigorous human validation of these temporally integrated representations and exploring adaptive temporal integration techniques that might vary with content. Our research lays a foundational groundwork, demonstrating that by more closely emulating human-like temporal processing, we can design video representations that offer a more nuanced alignment with human engagement, thereby advancing computer vision systems towards a more perceptually-grounded understanding of dynamic scenes.
7. References
- Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., & Vijayanarasimhan, S. (2016). Youtube-8m: A large-scale video classification benchmark. arXiv preprint arXiv:1609.08675.
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding? ICML.
- Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., & Schmid, C. (2021). ViViT: A Video Vision Transformer. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2021.
- Bylinskii, Z., Judd, T., Oliva, A., Torralba, A., & Durand, F. (2019). What do different evaluation metrics tell us about saliency models?. IEEE transactions on pattern analysis and machine intelligence.
- Grauman, K., Westbury, A., Byrne, E., Chari, V., ... & uncooked, R. (2022). Ego4D: Around the World in 3,000 Hours of Egocentric Video. CVPR.
- Li, J., Li, D., Savarese, S., & Hoi, S. (2023). BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. ICML.
- Pinto, J., Almeida, J. M., & Goncalves, M. A. (2019). Beyond Views: Measuring and Predicting Engagement in Online Videos. Proceedings of the International AAAI Conference on Web and Social Media, 13(1), 416-426.
- Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning (LLaVA). NeurIPS.
- Greene, M. R., & Oliva, A. (2009). Recognition of natural scenes from global properties: seeing the forest without representing the trees. Cognitive Psychology.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP.
- Schacter, D. L., & Addis, D. R. (2007). The cognitive neuroscience of constructive memory: remembering the past and imagining the future. Philosophical Transactions of the Royal Society B: Biological Sciences.
- Tong, Z., Song, Y., Wang, J., & Wang, L. (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training. NeurIPS.
- Zhang, H., Li, X., & Bing, L. (2023). Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. EMNLP.
- Wolfe, J. M., Võ, M. L. H., Evans, K. K., & Greene, M. R. (2011). Visual search in scenes involves selective and nonselective pathways. Trends in cognitive sciences.
- Del Viva, M. M., Retell, J. D., & Storrs, K. R. (2024). Continuous temporal integration in the human visual system. Journal of Vision, 24(1), 2.
- Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV.
- Fu, Y., Hospedales, T., Xiang, T., & Yao, Y. (2014). Interestingness Prediction by Robust Learning to Rank. ECCV.
- Hershey, S., Chaudhuri, S., Ellis, D. P., Gemmeke, J. F., Jansen, A., Moore, R. C., ... & Wilson, K. (2017). CNN architectures for large-scale audio classification. ICASSP.